테이블을 설계하다 보면 자기 자신을 참조하는 경우가 있다. 이를 JPA로 나타내자면 아래와 같다.
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Entity
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "parent_id")
private Category parent;
@Builder.Default
@OneToMany(mappedBy = "parent")
private Set<Category> children = new HashSet<>();
}

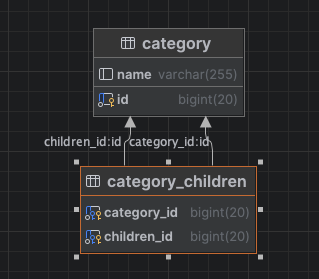
이와 다른 형태로는 아래와 같은데 이와 다르게 자식 테이블이 별도로 생성되어 이 경우 불필요한 join query가 불필요하게 발생되어 아래와 같은 방식 보단 첫번째 방식으로 계층형 테이블을 설계해야 한다
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Entity
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany
private Set<Category> children = new HashSet<>();
}
반응형
'SpringBoot > JPA' 카테고리의 다른 글
| Inheritance 전략 (0) | 2024.10.08 |
|---|---|
| Springboo3 으로 변경 했을시에 QueryDSL 변경 점 (0) | 2023.06.09 |
| 값 타입과 값 타입 컬렉션에 관한 사용법 (0) | 2023.04.07 |