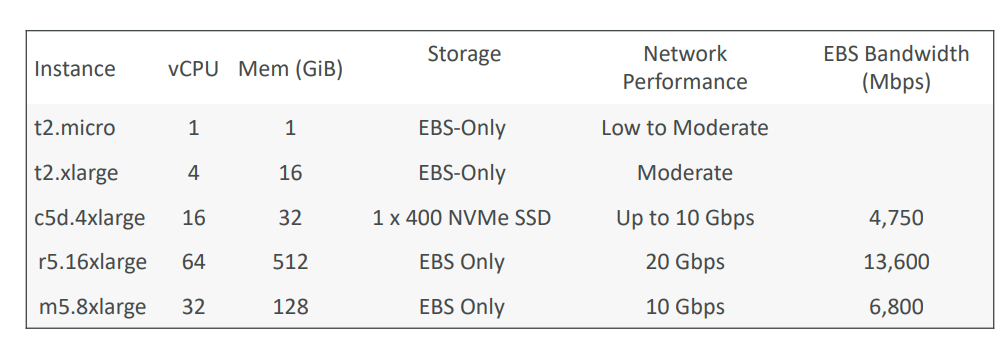
Springboot2로 운영되는 서비스를 Springboot3 로 버전 업을 하게 되었을 시에 javax 대부분의 패키지가 jakarta 패키지로 이관되어 기존 QueryDSL의 JPAQueryFactory는 javax.persistence 패키지를 참조하고 있어 호환이 불가능 하기에 아래처럼 수정하면 에러가 해결된다.
IAM 사용자의 집합으로서, 사용자 그룹을 활용하면 다수의 사용자들에 대한 권한을 지정함으로써 해당 사용자들에 대한 권한을 더 쉽게 관리할 수 있다. 사용자 그룹의 모든 사용자가 정책의 권한을 받도록 Identity기반 정책을 사용자 그룹에 연결할 수 있다. 그룹은 인증이 아니라 권한과 관련이 있고 보안 주체는 인증된 IAM 엔티티이기 때문에 정책에서 사용자 그룹을 Principal로 식별할 수 없다.
다음은 사용자 그룹이 갖는 몇 가지 중요한 특징이다.
Root accout 는 기본생성 되어지며 사용하거나 공유해서는 안된다.
조직내의 사용자들은 그룹화(사용자 그룹) 할 수 있습니다.
그룹에는 사용자만 포함할 수 있으며 다른 사용자 그룹은 포함할 수 없습니다.
사용자는 사용자 그룹에 속할 필요가 없으며 사용자는 여러 그룹에 속할 수 있습니다.
User & Group
IAM 역할
IAM 역할 은 계정에 생성할 수 있는, 특정 권한을 지닌 IAM 자격 증명이다. IAM역할은 AWS에서 자격 증명이 할 수 있는 것과 없는 것을 결정하는 권한 정책을 갖춘 AWS 자격 증명이라는 점에서 IAM 사용자와 유사하다. 그러나 역할은 그와 연관된 암호 또는 액세스 키와 같은 표준 장기 자격 증명이 없다. 때문에 역할을 맡은 사람에게는 해당 역할 세션을 위한 임시 보안 자격 증명이 제공된다. 이와 관련된 것이
AWS STS와 Assume Role인데
AWS STS(Security Token Service)는 AWS에서 보안 토큰을 생성하는 서비스이며, Assume Role은 AWS IAM에서 지원하는 기능 중 하나로써 AWS IAM에서 Assume Role을 사용하면 IAM 사용자 또는 AWS 외부 자격 증명으로 다른 AWS 계정 또는 리로스에 엑세스 할 수 있다.
IAM Permissions
사용자와 그룹은 JsonType document로 Policies(정책)를(을) 할당 받을 수 있으며 이러한 Policies는 사용자의 권한을 정의합니다.
최소한의 권한 정책을(least privilege principle)을 적용해야 하며 사용자가 필요로 하는 것보다 더한 권한을 주워서는 안된다.
IAM Policies inheritance (정책 상속)
정책 상속
IAM Policies Structure
구성 정보
Version: 정책 언어 버전(항상 2012-10-17일로 고정)
Id: 정책 식별자(선택 사항)
Statement: 하나 또는 그 이상의 개별 명령문(Statement)(필수)
Statement 구성 정보
Sid: 명령문의 식별자(선택사항)
Effect: 명령문이 액세스를 허용하는지 또는 거부 하는지 여부(Allow or Deny)
Principal: 이 정책이 적용될 사용자, 계정, 역할(Account, User, Role)
Action: 허용하거나 거부된 정책 목록
Resource : Action 이 적용된 리소스 목록
Condition: 이 정책이 적용되는 조건(선택사항)
IAM Password Policy
복잡한 암호는 계정의 보안을 강화시키기에, AWS는 비밀번호 정책을 다음과 같이 설정할 수 있다.
클린 아키텍처에 대해 공부하기전에 기존 계층형 아키텍처가 무엇이며 어떠한 단점으로 인해 클린아키텍처가 대두되었는지 알아 보고자 한다. 계층형 아키텍처란 전통적인 웹 애플리케이션 구조이며, 웹 계층, 도메인 계층, 영속성 계층으로 구성된 3계층 구조로써 아래 와 같은 구성 모습을 보인다.
계층형 아키텍처
사실 계층형 아키텍처는 견고한 아키텍처 패턴이다. 다만 계층을 잘 이해하고 구성해야만 하며, 웹 계층이나 영속성 계층에 독립적으로 도메인 로직을 작성할 수 있으며 원한다면 도메인 로직에 영향을 주지 않고 웹 계층과 영속성 계층에 사용된 기술을 변경할 수도 있으며, 기존 기능에 영향을 주지 않고 새로운 기능을 추가할 수도있다. 즉 잘 만들어진 계층형 아키텍처는 선택의 폭을 넓히고 변화하는 요구사항과 외부 요인에 빠르게 적용할 수 있다.
그렇다면 계층형 아키텍처의 단점은 무엇인가.
계층형 아키텍처는 데이터베이스 주도 설계를 유도한다.
계층형 아키텍처의 토대는 데이터베이스이다. 상위계층에서 하위계층으로 의존관계가 맺어지기에 웹은 도메인계층에 의존하고, 도메인 계층은 영속성 계층에 의존하기 때문에 자연스레 데이터베이스에 의존하게 된다. 이는 다양한 문제를 초래 할 수 있는데, 흔히 비지니스 로직을 구현하는데 있어, 상태가 아니라 행동을 중심으로 모델링한다고 표현하는데 어떤 경우에건 상태가 중요한 요소이긴 하지만 행동이 상태를 바꾸는 주체이기에 행동이 비즈니스를 이끌어간다고 할 수 있다. 그렇다면 영속성 계층을 토대로 만들었던 이유는 무엇인가.
그동안 관습적으로 만들어온 애플리케이션의 유스케이스는 도메인 로직이 아닌 영속성 계층을 구현했다고 볼 수있다. 필자 역시도 10여년전 개발했을 당시 영속성 계층부터 구현을 시작하여 웹으로 이어지는 구조로 개발을 했었다. 이는 데이터베이스의 구조를 먼저 생각하고, 이를 토대로 도메인 로직을 구현했다는 의미이다.
하지만 이는 비즈니스 관점에서는 전혀 맞지 않는 방법이라고 할 수 있다. 다른 무엇보다 도메인 로직을 먼저 만들어야 하며 그래야만 로직을 제대로 이해 했는지 확인 할 수 있다. 그리고 나서 이를 기반으로 영속성 계층과 웹 계층을 만들어야 한다.
지름길을 택하기 쉬어진다
전통적인 계층형 아키텍처에서 전체적으로 적용되는 유일한 규칙은 특정한 계층에서는 같은 계층에 있는 컴포넌트나 아래에 있는 계층에만 접근 가능하다는 것이다. 이 같은 유일한 규칙은 결국 아래 계층으로 갈수록 비대해질 수 밖에 없는 이유를 야기한다.
테스트하기 어려워진다
계층형 아키텍처를 사용할 때 일반적으로 나타나는 변화의 형태는 계층을 건너뛰는 것이다. 엔티티 필드를 단 하나만 조작하면 되는 경우에 웹 계층에서 무심코 영속성 계층에 접근을 하게 된다면 말이다. 이 경우 도메인 로직을 웹 계층에 구현하게 된다는 의미이며 이는 결국 유스케이스가 확장됨에 따라 더 많은 도메인 로직이 웹 계층에 추가될 것이며 이는 애플리케이션 전반에 걸쳐 책임이 섞이고 핵심 도메인 로직이 퍼진다는 의미이다.
또한 이는 웹 계층 테스트를 구현할 경우 도메인 계층뿐 아니라 영속성 계층도 모킹을 해야 한다는 의미이며 이는 단위 테스트의 복잡도가 올라감을 의미한다.
유스케이스를 숨긴다
개발자들은 항상 새로울 유스케이스를 짜는 것을 선호한다. 그러나 실제로는 새로운 코드를 짜는 데 시간을 쓰기보다는 기존 코드를 바꾸는 데 더 많은 시간을 쓰며, 앞서 논의 했듯 계층형 아키텍처에서는 도메인 로직이 여러 계층에 걸쳐 흩어지기 쉽고 또한 계층형 아키텍처는 서비스의 '너비'에 대한 규칙을 강제하지 않으며 이는 곧 넓은 서비스는 영속성 계층에 많은 의존성을 갖게 되고, 다시 웹 레이어의 많은 컴포넌트가 이 서비스에 의존하게 만든다.
동시작업이 어려워진다.
계층형 아키텍처는 모든 것이 영속성 계층 위에 만들어지기 때문에 영속성 계층을 먼저 개발해야 하고, 그 다음에 도메인 계층을 그리고 마지막으로 웹 계층을 만들어야 한다. 때문에 특정 기능은 동시에 한 명의 개발자만 작업할 수 있다.
또한 코드에 앞서 말한 서비스의'너비'에 대해 규칙을 강제하지 않기에 넓은 서비스 안에서 서로 다른 기능을 동시에 작업하기란 더욱 어려울 것이다. 풀어 얘기한다면 서로 다른 유스케이스에 대한 작업을 하게 된다면 같은 서비스를 동시에 편집하는 상황이 발생하고, 이는 병합 충돌과 잠재적으로 이전 코드로 되돌려야하는 문제를 야기하게 된다.
AWS VPC(Virtual Private Cloud)는 클라우드 환경을 퍼블릭과 프라이빗이 논리적으로 독립된 네트워크 영역으로 분리할 수 있게 해주는 서비스 이다. 아래에 내용을 본다면 IPv4 CIDR 이라는 내용이 존재하는데 IPv4 CIDR(사이더)에 대한 것은 링크를 통해 연결하겠다.
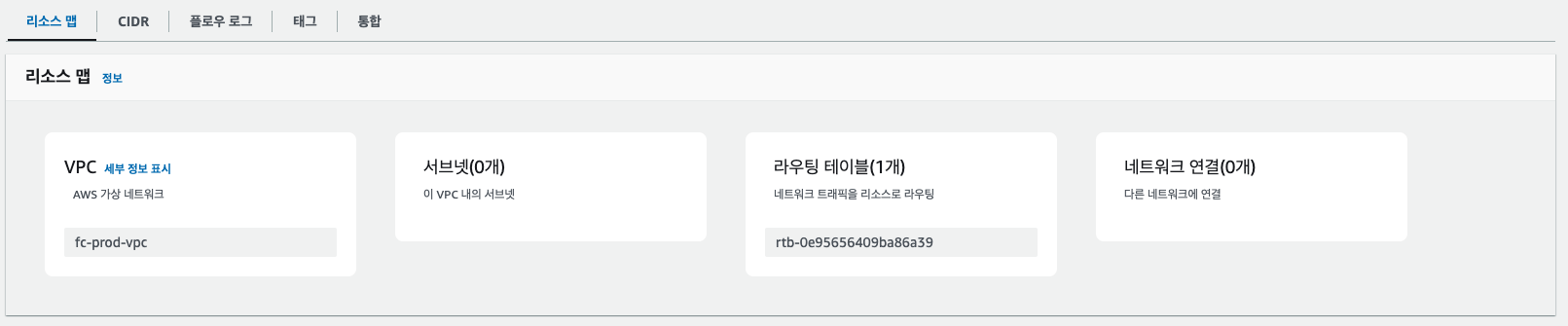
위와 같은 정보로 등록을 하게 되면 하위에 리소스 맵 탭에 다음과 같이 정보가 나온다.
위에 리소스 맵에 표기된 정보 외에 설정 정보들이 VPC 내에 존재하는데 그중 서브넷과, 라우팅 테이블, 인터넷 게이트웨이, NAT 게이트웨이에 대한 설명을 우선 적으로 진행하고자 한다.
Subnet
Subnet은 VPC를 특정 규칙에 의해 나눈 조각들이며, 하나의 Subnet은 하나의 AZ(Availablility Zone)에 할당 된다.
위에 신규 설정한 VPC ID를 선택하게 되면 아래처럼 IPv4 VPC CIDR 블록을 또 한번 잘게 쪼갤 수 있다 이때 통상적으로 private이 public 보다 더 잘게 쪼개 져야 하는데 그 이유는 public 영역에 할당될 IP들이 통상적으로 더 많아서 그렇게 하는게 Default이다.
또한 가용영역은 아래 처럼 a, b, c ,d 네개의 영역을 선택할 수 있으며 통상적으로 a 와 c를 default로 이용하게 되어있다. 그 이유는 가용영역 마다 올릴수 있는 ec2인스턴스에 대한 유형들이 달라 질 수 있는데 a, c에 올릴 수 있는 ec2 인스턴스 유형이 더 많기 때문이다.
VPC를 생성하게 되면 묵시적으로 내부에 라우팅 테이블이 생성되어 내부 서브넷간에는 통신이 가능하게 된다.
하위에 라우팅 테이블을 보면 묵시적으로 Name 이 '-' 된 테이블을 확인해 볼 수 있으며 클릭을 통해 서브넷 연결탭에 들어간다면 아래와 같이 명시적 연결이 없는 서브넷에 해당 VPC내에 위치한 서브넷이 등록이 되게 된다.
라우팅 테이블을 생성하게 된다면 VPC를 선택할 수 있으며 필자는 Public/Private 영역에 하나씩 라우팅 테이블을 생성하여 Public 영역과 Private 영역끼리 통신이 가능하게 하고자 한다. 앞서 '-' 로 표기된 기본 라우팅 테이블을 Public 라우팅 테이블로 변경해주고 Private 라우팅 테이블을 추가적으로 생성한다.
아래와 같이 두개의 rt를 생성했으며, 명시적으로 서브넷을 연결해야만 한다.
앞서 설정한 VPC와 Internet Gateway를 연결 시켜 외부와 통신가능하게 해야한다.
위의 인터넷 게이트웨이 생성 버튼을 통해 생성하게 되면 아래와 같이 VPC에 연결 버튼이 활성화 되고, 앞서 설정한 VPC에 연결을 하면 외부와 통신이 가능하게 된다.
다음운 NAT Gateway를 생성하고자 한다.
NAT란 Network Address Translation의 약자로 NAT를 이용하는 이유는 대개 사설 네트워에 속한 여러 개의 호스트가 하나의 공인 IP주소를 사용하여 인터넷에 접속하기 위함입니다.
예를 들면 외부 인터넷을 차단하고 내부에서만 사용하기 위해 만든 Private Subnet에 RDS을 넣어두고 이를 외부 인터넷을 통해 업데이트를 해야 할 일이 생긴다면 공인 IP를 생성해서 Internet Gateway를 연결해 줄 수 없기에(외부 인터넷 차단) 이 경우 사용하는 것이 NAT Gateway입니다. Internet 접속이 가능한 Public Subnet에 NAT Gateway를 생성해 두고 Private Subnet이 외부 인터넷으로 나아갈 경우에만 사용하도록 라우팅을 추가하는 것이다.
결론적으로 아래와 같이 통신을 하게 되는 것이다.
EC2 -> NAT Gateway -> Internet Gateway -> 외부 인터넷
아래는 NAT 게이트웨이 생성 부분이며 위에 말처럼 서브넷은 Public 영역에 위치시키고 탄력적 IP를 할당 해주워야 한다 그 이유는 외부서비스 이용시 내부 private 영역을 호출할때 고정 IP로 호출하지않으면 매번 IP가 달라져 외부서비스에서 설정 정보를 변경을 해주워야 하기때문이다.
@Entity
public class DeliveryJpaEntity {
...
@Embedded // 생략 가능
private AddressJpaEntity address;
...
}
@Embeddable
public class AddressJpaEntity {
private String address;
private String ji;
private String bun;
}
값 타입 컬렉션인 경우
- 값 타입을 컬렉션에 담아서 쓰는 걸 값 타입 컬렉션이라 한다.
- 값 타입 컬렉션은 영속성 전이(Casecade)와 고아 객체 제거(Orphan remove)가 Default 이다.
@Entity
public class DeliveryJpaEntity {
...
@ElementCollection // 기본 fetch 전략은 lazy 이다.
@CollectionTable(name = "delivery_item", joinColumns = @JoinColumn(name = "delivery_id"))
private List<DeliveryItemJpaEntity> deliveryItems = new ArrayList<>();
...
}
@Embeddable
public class DeliveryItemJpaEntity {
private String name;
private Long quantity;
private BigDecimal amount;
}
값 타입 컬렉션의 한계
엔티티는 ID로 DB에서 찾을 수 있기 때문에 쉽게 CRUD가 가능하나, 값 타입은 식별자라는 개념이 없기에 원본데이터를 찾기 어렵다, 값 타입 컬렉션은 별도의 테이블에 저장되는데 이 테이블 안에 있는 값타입의 값이 변경 되면 기존 값 타입 컬렉션을 제거하고 컬렉션 전체를 새롭게 저장하는 방식으로 이뤄진다. 때문에 컬렉션의 양이 많아지면 쿼리 수가 많아지기 때문에 컬렉션의 데이터가 많으면 값 타입 컬렉션 대신 일대다 관계 엔티티로 수정하는 것을 고려해야 한다.